Hello friends,
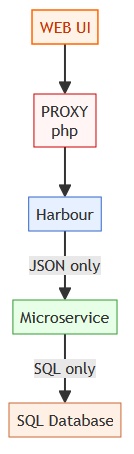
Harbour communicates with a microservice using JSON.
The microservice communicates with the database using SQL.
I believe SQL no longer belongs inside the Harbour process itself — not because SQL is bad, but because the environment around Harbour has fundamentally changed.
This is not a criticism of existing applications.
It is an observation based on how infrastructure, deployment, and runtime separation look today compared to 10–20 years ago.
Why this matters
In the past, embedding SQL directly into Harbour was often unavoidable:
no permanently running web servers
no lightweight local services
no clean separation between UI, business logic, and data access
The Harbour process itself was the server.
Today, this assumption no longer holds.
Web servers and microservices run continuously, SQL servers are already separate processes, and local service communication (socket / JSON / HTTP) is trivial — often on the same machine.
This opens a new option:
use SQL without embedding SQL clients into Harbour.
The idea in one sentence
Harbour talks JSON to a microservice.
The microservice talks SQL to the database.
Harbour never loads SQL DLLs.
Harbour never knows table schemas.
Harbour remains stable.
From DBF thinking to service thinking
Classic DBF code
USE kunden
GO TOP
DO WHILE !EOF()
? name, ort
SKIP
ENDDOService-based SQL access
hRes := ServiceCall( "kunden_list", { "limit" => 10 } )
FOR EACH hRow IN hRes["rows"]
? hRow["name"], hRow["ort"]
NEXT
Minimal Harbour client
FUNCTION ServiceCall( cAction, hData )
LOCAL hReq := { ;
"action" => cAction, ;
"data" => hData ;
}
RETURN hb_jsonDecode( SendToService( hb_jsonEncode( hReq ) ) )
FUNCTION SendToService( cJson )
LOCAL oSock := hb_socketOpen()
hb_socketConnect( oSock, "127.0.0.1", 9001 )
hb_socketSend( oSock, cJson + hb_eol() )
LOCAL cRes := hb_socketRecv( oSock, 8192 )
hb_socketClose( oSock )
RETURN cResSame usage pattern.
Different responsibility.
What runs where
Harbour
business logic
UI logic
JSON in / JSON out
Microservice (e.g. GraftonStreet Server)
SQL execution
prepared statements
transactions
Database
SQLite / PostgreSQL / MySQL
SQL lives behind the service boundary.
Why this is not overengineering
no SQL DLLs in Harbour
no OpenSSL, ODBC, libmysql in the core
no ABI or runtime conflicts
crash isolation by process separation
This is not adding complexity —
it is removing it from the wrong place.
Why this fits Harbour especially well
Harbour already works well with hashes and JSON
DBF-style thinking maps naturally to service calls
SQLite feels like DBF again (single file, easy backup)
migration can be incremental
For example:
USE kunden → ServiceCall( "kunden_list" )
Closing thought
SQL inside Harbour once solved an infrastructure problem.
Today, that infrastructure problem no longer exists.
What does exist today are better boundaries.
In the past, the Harbour process was the server.
Today, it can finally be just a client.
A possible role for FiveTech
I believe this is actually a task that fits very well with FiveTech’s role and experience.
Instead of every developer embedding SQL clients (libmysql, ODBC, OpenSSL, etc.) into Harbour applications, FiveTech could provide a small, built-in, service-oriented SQL layer, with the same level of quality and stability people expect from FiveWin / Harbour tools.
Conceptually, this would not replace SQL —
it would replace the built-in SQL clients.
Why this makes sense
The required surface is surprisingly small.
In practice, most applications only need a handful of well-defined operations:
execute a SELECT and get rows as hashes / JSON
execute INSERT / UPDATE / DELETE and get affected rows
insert a record from a hash
read table metadata (schema)
optionally: run multiple statements inside a transaction
That’s it.
Not an ORM.
Not a framework.
Just clean, predictable building blocks.
What FiveTech could standardize
FiveTech is in a unique position to do this once — correctly — instead of every project doing it differently.
A possible result:
a standard JSON protocol
a stable microservice reference implementation
a small Harbour client API (ServiceCall-style)
no SQL DLLs in Harbour processes
consistent behavior across platforms
Developers could then choose:
DBF backend
SQLite
PostgreSQL
MySQL
without changing application logic.
This is not about adding more abstraction.
It is about moving SQL to the right side of the boundary.
Harbour stays:
business logic
UI logic
orchestration
SQL stays:
isolated
replaceable
crash-safe
I’m not suggesting this should replace existing SQL integrations overnight.
But I do think it would be a very strong official alternative — especially for new projects.
Best regards,
Otto