Carlos,
FiveWiDi wrote:
Pero si quiero que todo lo el 'montaje' web trabaje en UTF8 y a su vez no tocar la app de escritorio, ¿Cómo debería gestionarlo?
No es una pregunta expresamente para ti.
Intento resumirlo el máximo posible, pero es bastante extenso, al final es un tema de como funciona correctamente los codepage de harbour. A mucha gente no le importa y al final pues hacen su pequeña rutina de conversión y ya lo tienen solucionado, pero no son las maneras correctas, no es una solución técnica correcta sino una solución chapuza.
Cuando creamos una aplicación en Harbour definimos un codepage , cuya función es gestionar ese mapa de caracteres, crear las reglas que nos servirá para ordenar índices, etc… Podemos usar por ejemplo HB_SetCodePage ( "ESWIN" ) en tu caso.
Nuestro objetivo es que las dbf estén limpias y saneadas. En cualquier proyecto se han de dejar siempre limpias e “higienizadas” antes poner en marcha el sistema.
Cuando abramos nuestra dbf con cualquier editor se habrían de ver absolutamente todos los códigos correctamente.
Escenario de vuestro problema -> Quiero usar una dbf que es parte de una aplicación de escritorio, pero también la quiero usar para una aplicación web, un caso típico.
Caso A – Codificar en UTF8
En el caso de que por lo que sea queráis usar una web codificada con utf-8 es necesario codificar la salida de datos hacia la web (toda la pagina web, incluido los datos de la dbf) a utf-8.
Para eso simplemente leyendo el contenido de la dbf compartida de los campos y creando la conversión con hb_StrToUtf8() es completamente suficiente, no necesitas nada mas.
Cuidado aquí, que cuando digo la salida hacia la web, porque a parte de los datos de la dbf, la codificación de la página ha de estar con utf8, esto lo debéis gestionar con el editor. Si en la página tenéis símbolos especiales, por ejemplo àèòñç… y la pagina está codificada en ansi, al viajar hacia el ordenador del cliente, intentara codificar a utf8 esa pagina y seria un desastre. Por esto es muy importante codificar con nuestro editor en utf8.
En el caso de Otto, por si lee este post, si tiene una dbf con su mapa de caracteres ‘DE’ , haciendo en su aplicación
HB_LANGSELECT('DE')
HB_SetCodePage ( "DEWIN" )
Y al leer su dbf, en cada campo aplicar la conversión hb_strtoutf8(), ya seria suficiente
cName := Hb_StrToUtf8( FIELD->name )
Hasta aquí ya tenemos la primer parte DBF -> Convertimos a UTF8 -> HTML
Ahora viene una de las partes mas importante y atañe al conocimiento de como funcionan los codepages. Cuando usamos HB_LANGSELECT() indicamos el idioma de nuestro sistema, por defecto cojerá un codepage asociado al idioma a no ser que lo seleccionemos. Si no indicamos nada en la aplicación el codepage es ‘EN’.
Si tenemos un simple formulario en web con utf8
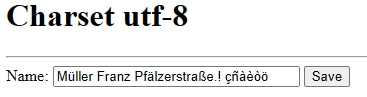
En este caso si nosotros convertimos la cadena que nos viene de la web de utf8 a string cojeria el mapa de caracteres ‘EN’ y en nuestra dbf nos aparecería
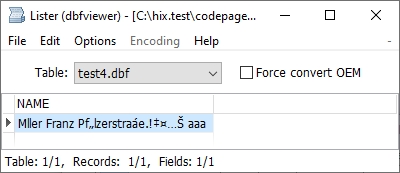
En este caso podríamos forzar nuestra dbf a que se salve con el codepage ‘DEWIN’ independientemente del codepage que use nuestra aplicación que ahora es ‘EN’ usando la clausula codepage
use ( hb_dirbase() + 'codepage/test4.dbf' ) EXCLUSIVE NEW CODEPAGE 'DEWIN'
En este caso la transformación quedaría perfecta
Müller Franz Pfälzerstraße
HTML -> Convertimos de Utf8 a string -> DBF
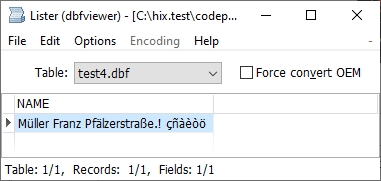
Para no tener que forzar a abrir las tablas dbf con el codepage que necesitemos usaremos:
SET( _SET_DBCODEPAGE, 'DEWIN' )
Esto fuerza a que nuestras dbf por defecto a no ser que indiquemos lo contrario usen este codepage. La configuración por defecto en nuestra aplicación al arrancar podría ser en este caso esta:
HB_LANGSELECT('DE')
HB_SetCodePage ( "DEWIN" )
SET( _SET_DBCODEPAGE, 'DEWIN' )
Resumen:
Configurar bien el codepage que usaremos en nuestra aplicación
Lectura para la web -> <cVar> := hb_StrToUtf8( <cField> )
Lectura web a dbf -> FIELD->name := hb_Utf8ToStr( <cParam> )
Caso B – Codificar en ISO
Si en usaras una dbf en la que tendrás tu mapa de caracteres de siempre y no piensas grabar caracteres especiales fuera de tu “lenguaje” natural… para que usar utf-8 ?.
UTF-8 es recomendado para usar hoy en día en la web, pero no significa que podemos usar otro sistema que se adapte mejor a nuestras necesidades. Imaginemos que solo queremos una web de información que se nutre de información de nuestra dbf. O un simple formulario de entrada de datos, o algún caso que se pudiera adaptar a nuestro escenario. Podríamos perfectamente codificar la web con el mismo charset que usamos y listos. NO necesitaríamos recodificar nada para publicar en la web.
En este caso, simplemente creando nuestra web (codificada con nuestro editor con ansi) con un meta ISO asi:
<meta charset='ISO-8859-1'>
Es suficiente para mostrar tal cual nuestra dbf, y si creáramos un simple formulario en esa web, el navegador enviaría los datos del formulario en ISO-8859-1
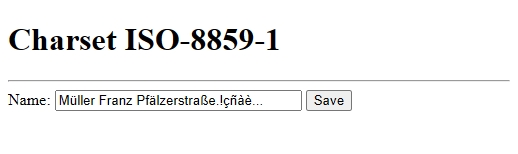
Que significa esto ? Si en este escenario nosotros iniciamos nuestra aplicación con nuestro codepage y el manejo de la dbf, NO necesitarías convertir el dato para pasarlo a la web y NO necesitarías convertir de la web los datos para salvarlo en la dbf
DBF -> HTML
HTML -> DBF
Se ha de estudiar bien cada caso y saber las opciones que tenemos y nos encontraremos, siempre que se pueda se ha de codificar en utf8, mas si usaremos técnicas como ajax, interfases con apis, … pero esto no implica que no podamos usar varias metodologías.
HIX – Configuracion
HIX ya configura todo esto. Con el comando “harbour” podemos definir nuestro lenguaje. Esto configurara el lenguaje que se usara en HIX, su codepage y configurara como tratara por defecto los dbfs
Creé hace tiempo en el manual unos capítulos sobre el charset, que aunque esta enfocado a Tweb el contenido es completamente valido para entender aun mas todo este tema. Lo podeis encontrar en https://carles9000.github.io/index_doc_en.html?search=TWEB%20manual , buscad en el índice “charset”
Final del "simposium" :D
En Harbour tenemos la capacidad de encontrar soluciones de muchas maneras, pero se trata de aprender con el tiempo como funciona internamente y evitar malas practicas que si nos pueden salvar de un apuro no son la mejor recomendación. Yo recomiendo ir aprendiendo correctamente esta manera de trabajar, entender el porque y trabajar la web con utf8. Si entendemos como funciona harbour simplemente con hb_StrToUtf8() / hb_Utf8ToScr() tenemos suficiente y sino… algo mal estamos haciendo.
Recomiendo crear pruebas con estos casos para acabar de asimilar bien los conceptos... :wink:
C.